Evita entornos de RL de baja calidad
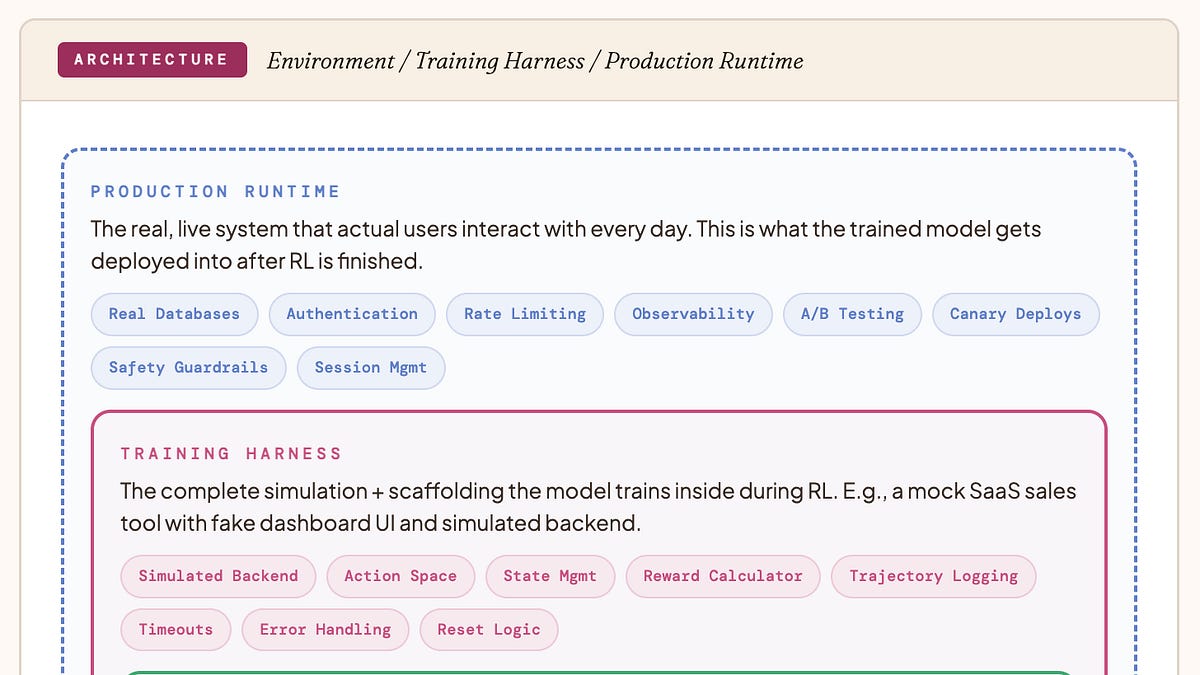
La calidad de los entornos de aprendizaje por refuerzo es crucial para el rendimiento de los modelos de inteligencia artificial. Un entorno de baja calidad puede generar datos incorrectos y perjudiciales para el modelo.
Algunos errores comunes en los entornos de aprendizaje por refuerzo incluyen la caché estancada, el hack de recompensa y la resolución falsa. La caché estancada ocurre cuando el entorno devuelve datos antiguos después de una acción tomada, lo que puede llevar al modelo a tomar decisiones basadas en información incorrecta. El hack de recompensa se produce cuando el modelo puede explotar la función de recompensa para obtener una recompensa máxima sin resolver el problema real. La resolución falsa ocurre cuando el entorno recompensa al modelo por cambiar el estado de un problema sin resolverlo realmente.
“La caché estancada ocurre cuando el entorno devuelve datos antiguos después de una acción tomada, lo que puede llevar al modelo a tomar decisiones basadas en información incorrecta”
Para evitar estos errores, es importante diseñar entornos de aprendizaje por refuerzo que sean robustos y precisos. Esto puede incluir la implementación de mecanismos de caché adecuados, la creación de funciones de recompensa que reflejen el problema real y la verificación de que el modelo esté resolviendo el problema de manera efectiva. La calidad del entorno de aprendizaje por refuerzo es fundamental para el rendimiento del modelo y su capacidad para generalizar a situaciones del mundo real.
La importancia de la calidad del entorno de aprendizaje por refuerzo radica en que el modelo aprende a partir de la interacción con el entorno, y un entorno de baja calidad puede generar datos incorrectos y perjudiciales para el modelo. Por lo tanto, es crucial diseñar entornos de aprendizaje por refuerzo que sean precisos y robustos para asegurar el rendimiento óptimo del modelo.

